
Motivation
There are a lot of tutorials available online on how to solve specific problems in different programming languages. However, there are few that teach the philosophy of developing a reasonable sized production quality project end-to-end with examples. For this, my favorite resource is this series of blog posts by Jeremy Kun. In this series, he explains how to solve a problem using good programming practices in Python. This includes setting up a project using git, test-driven development, using a database, deploying the project on cloud, scaling and productionizing. I consider these absolute gold on the internet and suggest it to young developers when they’re starting out with programming as an example of how to build a project brick-by-brick.
I found this resource a few years back and went over it in detail as a read-through. I have been wanting to follow it step-by-step in Python as Kata to make sure that I understand the details of how he went through each step. However, recently, after getting fascinated with Golang - I was wondering if I could try to recreate the same in Golang instead of Python, enabling me to reify the techniques of software engineering, as well as learning Golang in one shot.
I’m planning to chronicle my progress on this, in a series of blog posts, and on this github repo, starting with this one. I will be closely following along the same path as the original with the same structure. I will try to explain the differences from the source, to keep this fairly self-standing, but to get the full benefit it might make sense to read the original blog post as well.
Jeremy Kun has graciously given permission to use his post as a source. Thanks Jeremy!
Riemann Hypothesis
Riemann Hypothesis is a conjecture that can be stated quite simply as (from Wikipedia):
The Riemann zeta function has its zeros only at the negative even integers and complex numbers with real part $\frac{1}{2}$
This seems fairly simple, but turns out to be quite difficult to understand, let alone try to find a proof for. It is considered one of the “celebrity” math problems that is still unsolved (especially now that Fermat’s Last theorem is no longer in the running) and is one of the unsolved Hilbert Problems and one of the Millennium Prize problems worth a cool $1 Million. One of the ways the problem can be expressed is using a simpler formulation proposed here, which John Carlos has paraphrased, as:
find a number n > 5040 whose sum of divisors, divided by n ln(ln n), is more than $e^γ$ where $\gamma$ is Euler’s constant.
This kind of a problem formulation is called finding a witness in mathematics, where you’re trying to prove or disprove a theorem by finding a single number that follows a particular criterion. In our case, we need to find a number such that:
$$ \frac{\phi(n)}{n \log(\log(n))} > 1.782$$
Where $\phi(n)$ represents the sum of divisors of $n$. We’re trying to do the same by manually searching for the witness, number by number, in Golang!
Preliminaries
We start out by setting up the project by starting a new repo on Github in this commit. We can select Go as a language to get a .gitignore file for free in addition to adding the MIT license. A basic readme is also added which is improved further here to explain the motivation of this project.
Setting up go modules
Go has the concept of a module, which is a collection of Go packages stored in a file tree. Similar to the python __init.py__ file, adding a go.mod file at the root of a tree makes it a Go module. Within the module, each folder is considered its own package. From the official docs:
The go.mod file defines the module’s module path, which is also the import path used for the root directory, and its dependency requirements, which are the other modules needed for a successful build
In our case, we just define the module now in this commit. We will add further dependencies as and when they’re used.
Setting up tests
Before we write any code, we are going to start by setting up the tests. The first function we’re going to add is the DivisorSum function which calculate the sum of divisors for a number. We can setup the testing without any implementation to get a failing test here.
We started out making testing as part of the riemann package which contains the code. In this commit, we move it over to a separate riemann_test package which allows us to interact with the riemann package only through the public API. There are pros and cons to both approaches, but for this project, we’re not going to worry too much about which fields and methods should be public or private (in a real project, this is something you should worry about!), so the difference is mostly stylistic.
Improving testing
Once we have basic testing in place and working (you can test that this is failing by running go test on the terminal), we can move to a better testing package. In my case, I’m using Ginkgo. Along with the Gomega matching/assertion library (almost always used in conjunction with Ginkgo), Ginkgo allows us to write more expressive tests, which almost read like plain English rather than having a million if-else statements with the basic testing library.
For example, while the previous test case was simple enough with:
func TestDivisorSum(t *testing.T) {
sum := DivisorSum(195)
fmt.Println(sum)
if sum != 72 {
t.Fatal("Divisor sum doesn't match!")
}
}
In case of a failing error, the basic testing package outputs that the test has failed, unless any additional info is provided manually by the developer. Instead Ginkgo allows you to write the same test as
var _ = Describe("Divisor", func() {
Context("Good Cases", func() {
It("Should give correct result", func() {
output, _ := riemann.DivisorSum(72)
Expect(output).To(Equal(195))
})
}
}
which is arguably much easier to read. More importantly, when an error is encountered, you get a nice error message like
Divisor
/Users/alexsanjoseph/Learning/riemann-divisor-sum-go/riemann/divisor_test.go:9
Good Cases
/Users/alexsanjoseph/Learning/riemann-divisor-sum-go/riemann/divisor_test.go:11
Should give correct result [It]
/Users/alexsanjoseph/Learning/riemann-divisor-sum-go/riemann/divisor_test.go:12
Expected
<int64>: 195
to equal
<int64>: 192
/Users/alexsanjoseph/Learning/riemann-divisor-sum-go/riemann/divisor_test.go:17
which allows us to debug the issue easily.
With such a simple test, the value proposition might not be clear enough, but when the test suite gets larger and larger, having a dedicated testing library really helps to keep the code maintained and clean.
Installing ginkgo/gomega libraries also pull in a bunch of indirect dependencies. All of these are marked in the go.mod file along with the hashes in the go.sum file which is very similar to package-lock.json in NodeJS or Pipfile.lock in Python.
All of the above changes can be seen in this commit.
In addition, I have also installed the GoConvey package, which automatically runs my tests on every save and gives me a fancy UI (an example is shown below) to show if the tests have passed or failed. (This is not captured in a commit because I have installed it globally for my other projects)
Divisor Sum - Naive implementation
Now that we have the basic scaffolding in place, let’s go ahead with the implementation. To calculate the sum of divisors of a number, we have implemented a Naive algorithm which runs through every integer and checks if the said integer is a divisor. We can check that the algorithm is working (and failing) correctly by adding a bunch of tests for the different use cases. The tests are added here.
Currently we have only one testing file and hence having the test suite handler in the file is alright, but we expect that to change pretty soon once we have more files. Hence in this commit, I have moved test handler to separate file for cleanliness.
In the previous commit, I had lazily avoided checking for errors using the underscore(_) variable, which is considered a bad practice. I have fixed that and added tests for errors in this commit.
Counterexample search
Now let’s come to the the counterexample search which forms the meat of the problem. In this commit, we’ve added three functions:
WitnessValuewhich takes in a number and gives the Witness for that number,Searchwhich searches across a range of numbers if a Witness exists, andBestWitness**` which finds the highest witness value in a range of numbers
Tests for the same have also been added, as always.
Profiling in Go
Although our search program is ostensibly working now, as evidenced by the tests, it is excruciatingly slow. Searching across the first 100K integers using the current implementation takes ~4 seconds, and 500K integers ~1.5 minutes, which is ridiculously slow if we are to reach anywhere in the large numbers.
To find out the bottleneck causing the program to run slow, we need to profile the code. Thankfully, Go has profiling implemented natively in the standard library and since we have tests for the same, this can be done very easily with
go test ./riemann -cpuprofile profile.out
This command profiles the test code and outputs the profiling info into profile.out. The results can be visualized using the command
pprof -http=localhost:10000 profile.out
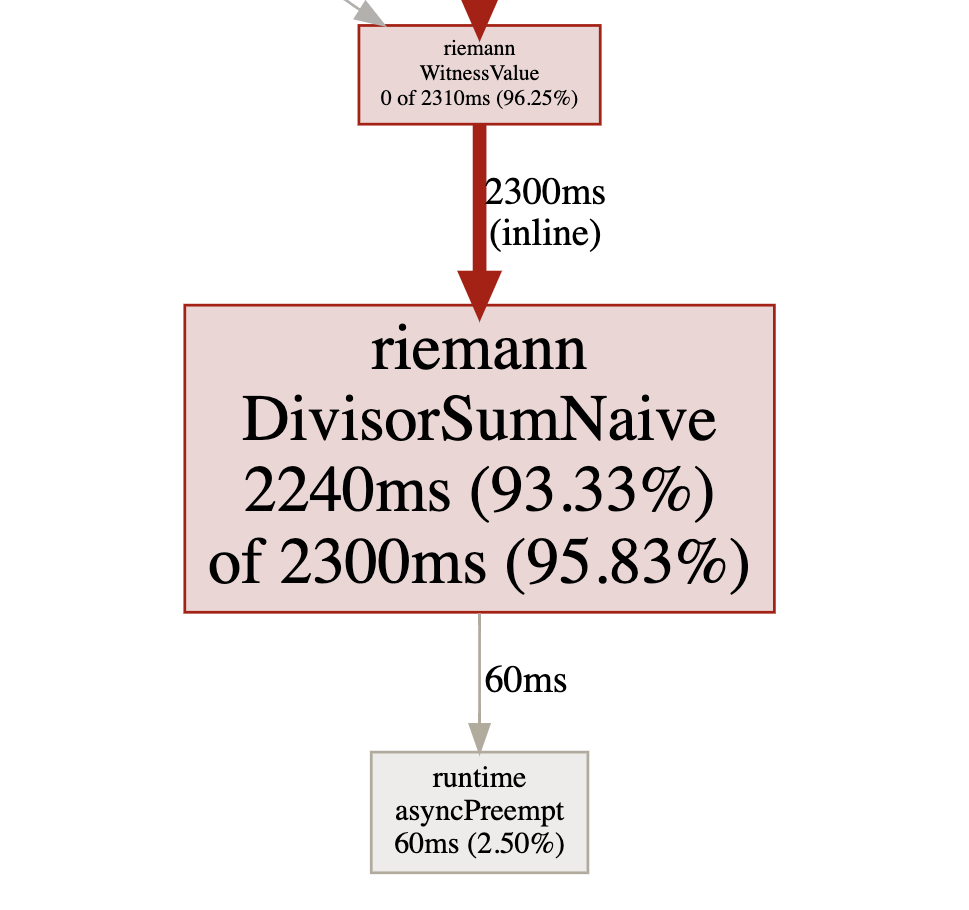
Turns out that most of our time is spent calculating in the DivisorSum! It is easy to see that we have a time complexity of $O(n^2)$, one $n$ for the loop and one $n$ since we’re going all the way up to the number, We need to find ways to improve this function.
Improving implementation
Before we go about improving the implementation, we add some additional tests to make sure that we’re not breaking any functionality. Copying the steps in the original post, there is an approach by Euler which recursively uses the results from a previous computation to calculate the Divisor Sum. In our case, since we’re linearly searching across all the numbers, this allows us an opportunity for memoization and hence improved efficiency.
In this approach, we’re trading computation complexity for space complexity (by caching all the previous computations) and for this we need to use some kind of cache. The original implementation uses the LRU cache, but we’re going the simple route and instead using a simple hashmap as a cache, since we don’t worry too much about memory constraints.
On rerunning the tests, we can see that the functions are running much 2-3x faster for our samples. Faster, but not fast enough. It is still taking 2.6 seconds for calculating up to 100K.
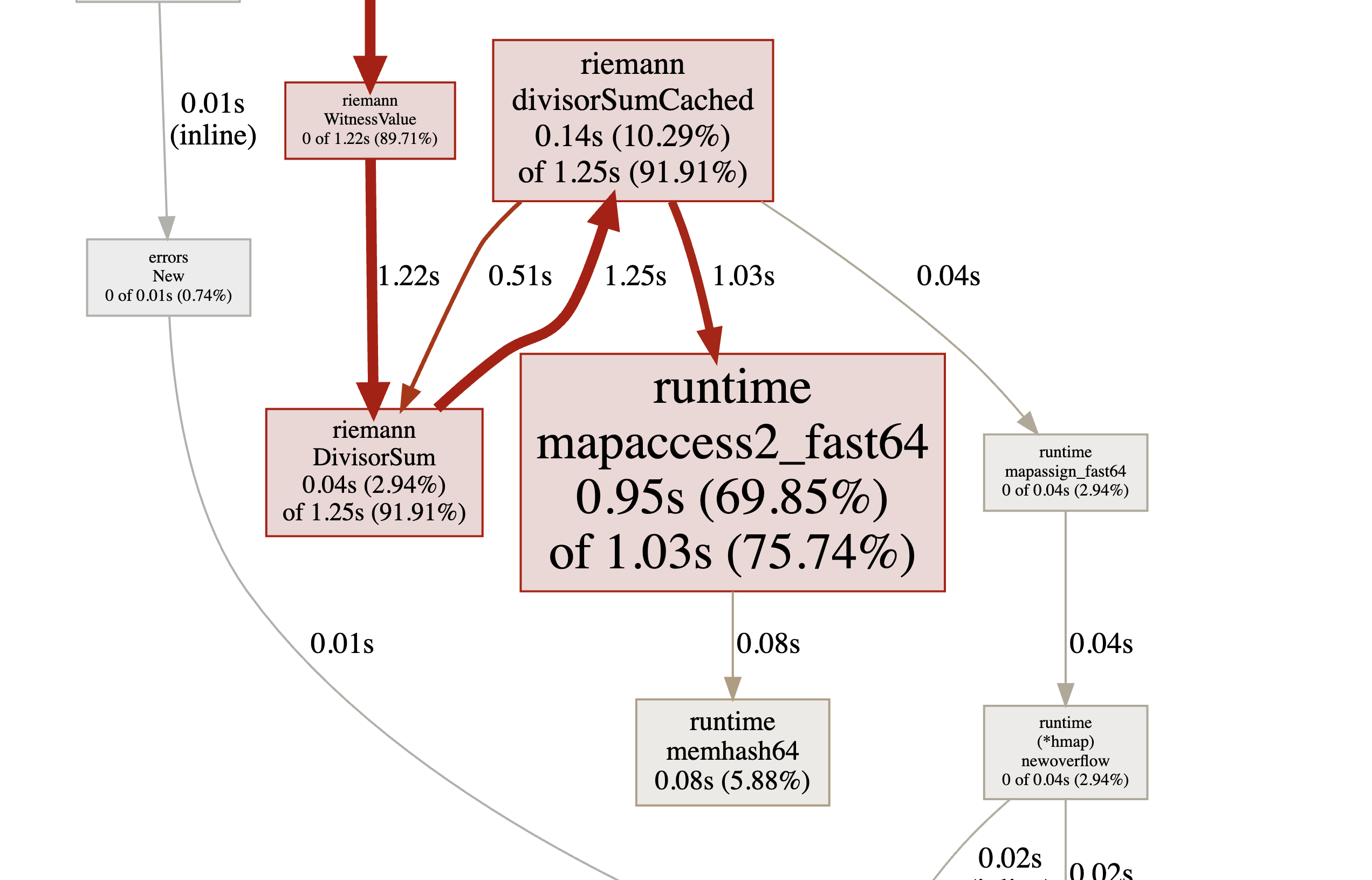
Rerunning the profiling, we can see that it is spending lesser time calculating the Divisor sum, but now there is definite overhead associated with the caching which is slowing things down.
Simpler/Faster
If we look at the algorithm, we can see that we still have a time complexity of $O(n^{\frac{3}{2}})$. This same complexity can be achieved by a much simpler implementation of the naive algorithm by only computing the divisors up to $\sqrt n$ instead of blindly counting all the way up to $n$ implemented in this commit. It also gets rid of the caching since that’s not relevant anymore.
Rerunning the tests, the change is incredible, we’ve gotten a benefit of two orders of magnitude in the tests and calculating up to 1M which used to take a minute happens in under a second now! We can now calculate all the way up to 10M in ~15 seconds as we can see from the GoConvey test output below.
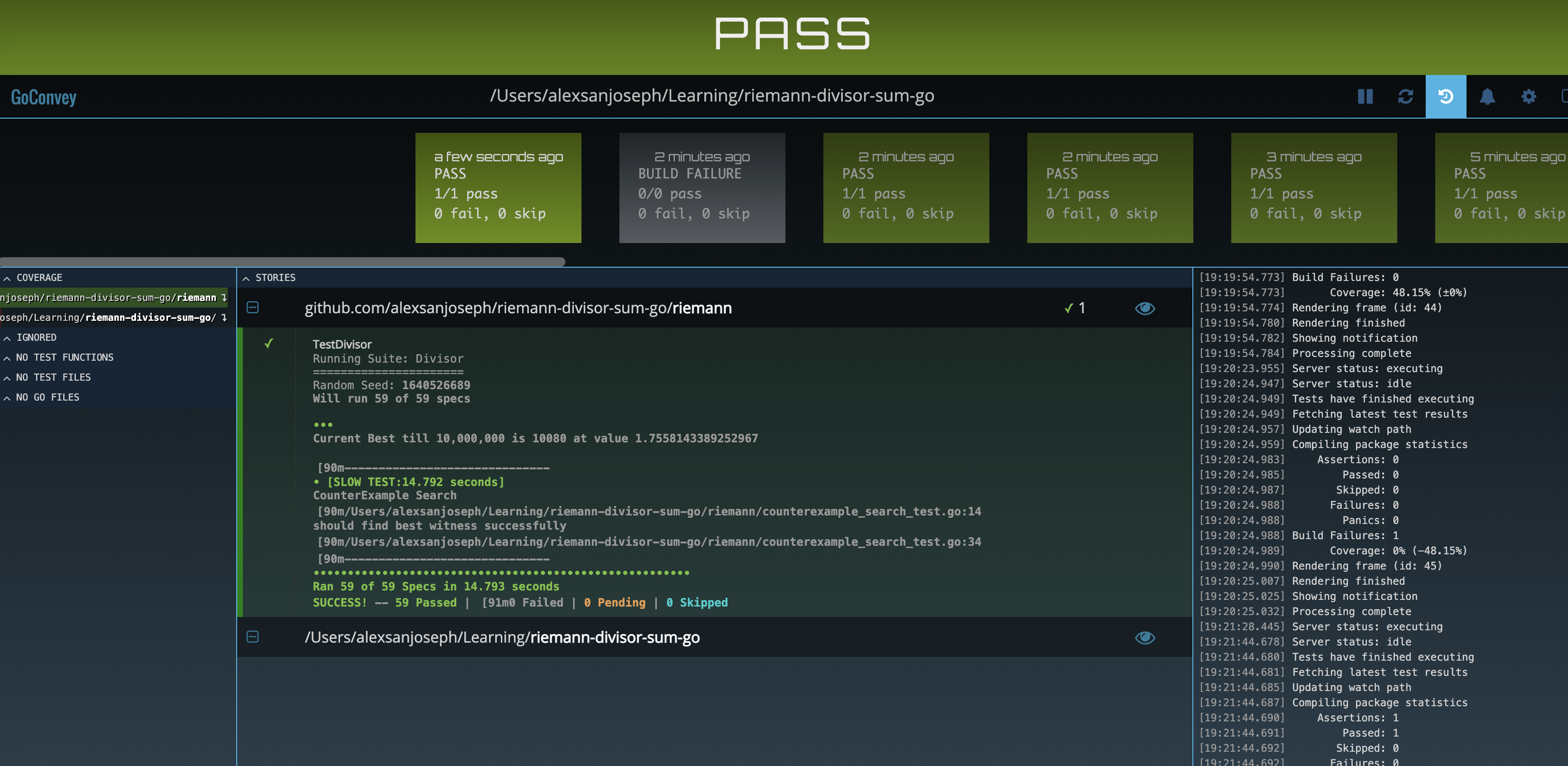
open in separate window to zoom
At this point in the implementation, Jeremy usesnumbainPythonto invoke Just-In-Time compilation to make the python program more efficient. However, sinceGolangis already compiled, we don’t need to do any of that! Even withnumba, tests inPythonare twice as fast inGolang!
Now that we have the implementation set correctly, we can improve the test output better using an additional package. I also removed the inferior implementation since we’re no longer planning to use them (we can always get them back any time thanks to Github!)
Benchmarking
Final results of the different implementation times are given in this table -
| Implementation/Time(s) | 100K | 200K | 500K | 1M | 10M |
|---|---|---|---|---|---|
| Naive | 4.2 | 16 | 86 | - | - |
| Cached Python (from original post) | 50 | ? | ? | ? | ? |
| Cached Golang | 2.6 | 6.3 | 26 | - | - |
| Square Root Python (replicated locally) | 0.06 | 0.14 | 0.46 | 1.2 | ~25 |
| Square Root Golang | 0.021 | 0.05 | 0.204 | 0.6 | ~15 |
We can clearly see both the power of algorithms, and the power of programming languages 😉
Conclusion and Next steps
In this blog post, we went over setting up a project, and basic implementation of a few different algorithms in Golang. In the next post, we will bring in a database to persist our output rather than calculating the results every time from scratch.
Credits: Thanks to Vishnu Shankar for reminding me on the importance of keeping the control variables constant in experimental design!