
Introduction
Are you in the Kubernetes bandwagon yet? We at VIMANA are fully bought into the ecosystem, which has been working out great for us because of the amazing abstractions and the ease of operations once everything has been properly setup. One thing that Kubernetes does is Automatic Bin Packing wherein the Kubernetes smartly allocates the pods on the the available nodes depending on the resource requirements. In AWS, Automatic scaling groups allow the system to expand and contract based on ephemeral demands, making sure that resources are not wasted when not required.
Most of the time with cloud providers, we use a generic instance with autoscaling groups, say m5.xlarge, m5.2xlarge etc. Suppose the entire app requires 100 CPUs and 400 GB ram, we could use 100 m5.xlarge or 50 m5.2xlarge. While this satisfies the resource requirements, there are two places where we have an opportunity to optimize the nodes instead of using the generic ones:
-
The required cluster use case might be either RAM or CPU intensive - For example, in AWS, an
m5.xlargeinstance has 4 CPUs and 16 GB RAM. However, if the total resource requirement of all the applications is say 16 CPUs and 20 GB RAM, the node groups will be autoscaled to create 4 instances to account for the CPU requirement causing 64 - 20 = 44 GB to be wasted. In this case, using a CPU heavy instance likec5.xlargecould be more benefical. -
Although in general, the cost of the servers scales proportionally to the amount of resources being used, it is not uncommon to find deals on particular regions where some instances are significantly cheaper than others, probably because of a lack of demand. For example,
m5.2xlargewhich has 8 CPUs and 32 GB RAM is generally twice as expensive as am5.xlarge, but if it is actually 1.8x, instead of 2x, it makes sense to use the former preferentially.
For many of these questions, the best place to start is at https://www.ec2instances.info which has all the information required to compare different instances to see what is your best case solution.
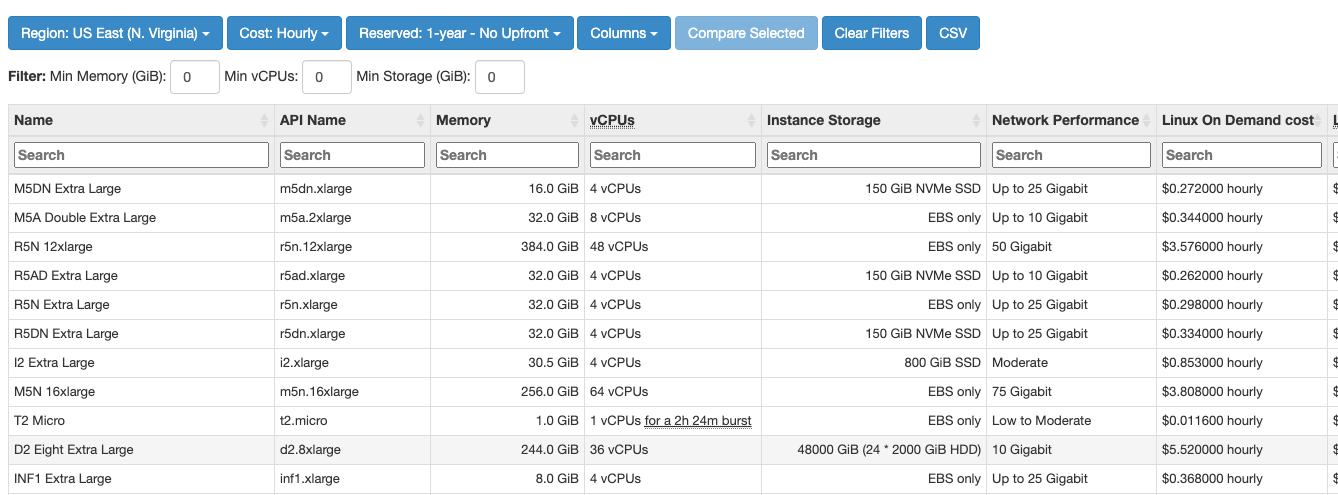
However, the actual optimization problem is still difficult to tackle manually since there are a large number of instance types to choose from, each having it’s own RAM/CPU/Total costs. Still, if we could cast this as an optimization problem, we should be able to let the computer do the hard work for us!
Optimization logic
This problem can be treated as an Linear Integer Optimization problem with the following components.
- Constants
- Cost of instance type
1-$c_{1}$ - Cost of instance type
2-$c_{2}$ - …
- Cost of instance type
m-$c_{m}$
- Cost of instance type
- Variables
- Number of instance type
1-$n_1, n_1 \in \mathbb{N_0}$ - Number of instance type
2-$n_2, n_2 \in \mathbb{N_0}$ - …
- Number of instance type
m-$n_m, n_m \in \mathbb{N_0}$
- Number of instance type
- Objective function
$\underset{n_1, n_2, ..., n_m}{\arg \min} \sum\limits_{i=1}^m c_i * n_i$
- Constraints
$\text{CPU}_1 * n_1 + \text{CPU}_2 * n_2 + ... + \text{CPU}_n * n_m >= \text{CPU}_{\text{required}}$$\text{RAM}_1 * n_1 + \text{RAM}_2 * n_2 + ... + \text{RAM}_n * n_m >= \text{RAM}_{\text{required}}$
Now this can solved by any Linear Integer Optimizer out of the box. For this project we use the PuLP.optimizer. The relevant code snippet is provided below.
def best_reco(required_resources, instance_df):
prob = LpProblem("InstanceRecommender", LpMinimize)
instances = instance_df['name'].values
instance_dict = instance_df.set_index('name').T.to_dict()
instance_vars = LpVariable.dicts(
"Instance", instances, lowBound=0, cat='Integer')
prob += lpSum([instance_dict[i]['price'] * instance_vars[i]
for i in instances])
prob += lpSum([instance_dict[i]['vcpus'] * instance_vars[i]
for i in instances]) >= required_resources['vcpus']
prob += lpSum([instance_dict[i]['memory'] * instance_vars[i]
for i in instances]) >= required_resources['memory']
prob.solve()
print("Status:", LpStatus[prob.status])
best_reco = pd.DataFrame([
{'name': remove_prefix(v.name, "Instance_"), 'units': v.varValue}
for v in prob.variables() if v.varValue > 0]
)
best_reco = best_reco.merge(instance_df)
return best_reco
Wrapping it into an Application
For making this into an app, we chose to use Streamlit. We’ve written in detail about making a Streamlit app and hosting it yourself for free here. In this app, we follow the following high level steps:
- Get the requirements from the user
- Memory and CPU
- Region
- Architecture
- Other constraints (Allow burstable, regex search etc.)
- Min and Max instances sizes allowable
- Filter for instances in the region and pass on the constraint optimization problem into the LP solver
- Display the optimal output in a table
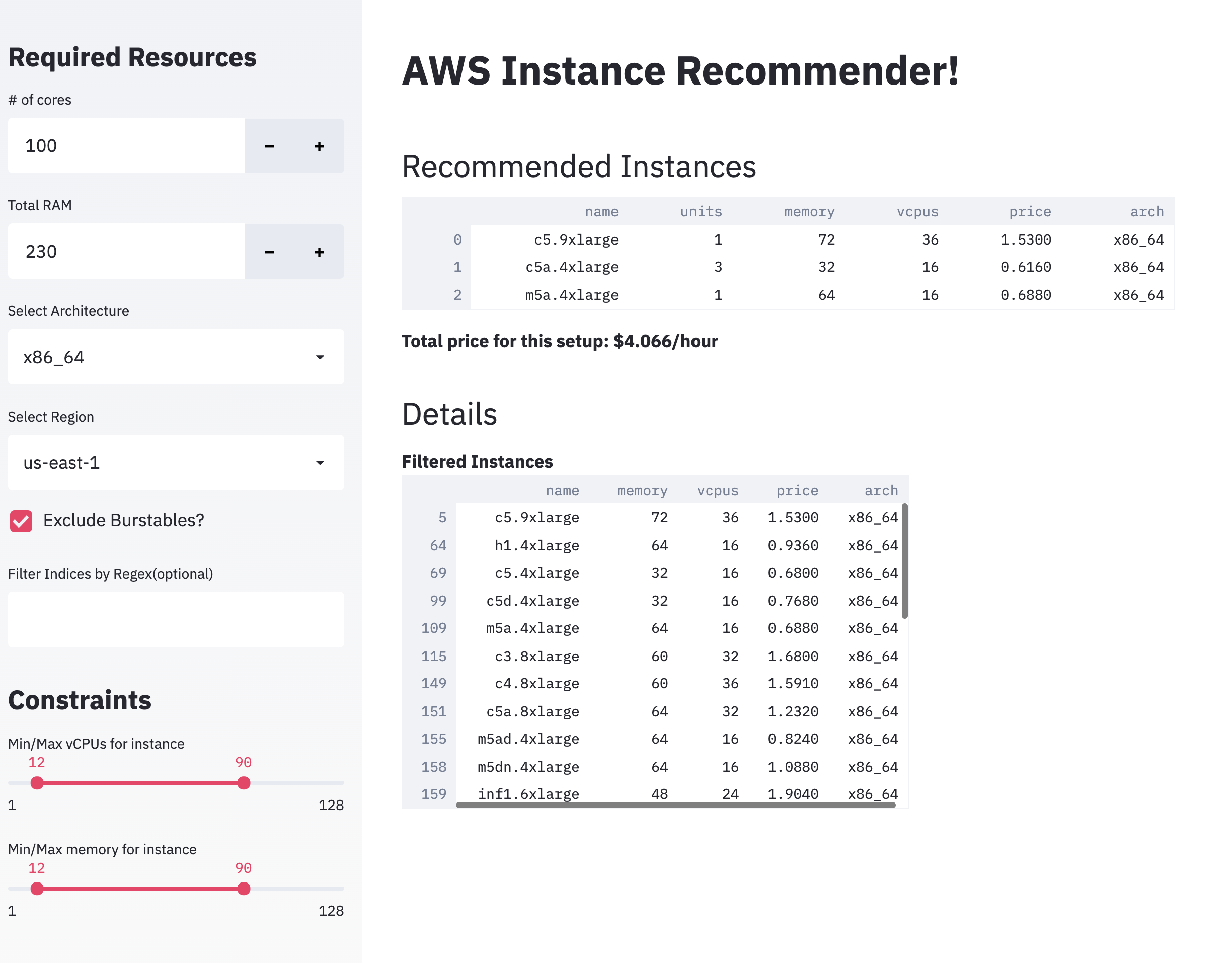
Try it out
You can checkout the app in action here (using streamlit sharing) and here (using heroku, please wait 30 seconds for the very first load since this is on the free tier!).
Host it yourself!
Instructions on how to host the app yourself can be found in the project homepage.
Credits
This work was done in collaboration with Anish Mashankar. Also thanks to VIMANA for giving us the the freedom to spend money to save money!
Caveats
- This blog post is based on AWS, but the concepts should translate to GCP/Azure and other cloud providers as well
- We’re using just CPU + RAM as the requirements, but it should be possible to extend it to network bandwidth, disk space, etc. if required.