

There’s been plenty written about individual AI coding experiences (some by me), but what I haven’t seen much of is how working with AI changes when you’re actually part of a team. This feels like something we have all collectively ignored although most of us are working in teams in this brave new world we have found ourselves in.
At Netrin, we’ve had to rethink several core software engineering processes, and we’ve found pretty good results with the changes.
We primarily use Claude Code for development work. We previously used Cursor but have transitioned almost entirely to Claude Code for our day-to-day coding and automation workflows.
Before we start
Important caveat up front: everything I’m describing works for us as a small team at Netrin. We’re 6-8 people - designers, frontend developers, backend engineers - all pretty high-functioning. While this setup works for us, I’m honestly conflicted about how any of this scales to larger organizations.
The processes I’m about to describe are specifically calibrated for small, tight-knit teams. Your mileage may vary dramatically at enterprise scale.
What Changed for Us
Shorter Iteration Cycles
First major change: our personal velocity did increase dramatically. We used to run two-week iterations - pretty standard stuff. We have very light agile processes with daily 10-15 minute stand-ups and bi-weekly backlog refinement sessions. Most stories would take 1-2 weeks from start to finish.
With AI doing the heavy lifting, we can now complete full cycles (design to deployment and validation) within a single week for most stories. This shift to one-week iterations has made us significantly more agile.
The PR Avalanche
Without exaggeration, AI writes about 90-95% of our code now. This creates an interesting problem as a team - we’re spending most of our time reviewing PRs rather than writing code and constantly stepping on each other’s toes.
We used to have 4-5 PRs across our entire two-week sprint. Now we’re dealing with 5-10 PRs in flight at any given time within a single week.
The volume of PRs led us to adopt stacked PRs as a standard practice. When one person’s work depends on another’s, we stack the PRs and merge upstream changes downstream. This keeps everyone’s changes in the staging environments intact during the deployment chain.
With so many PRs in flight, ordering becomes critical. We’ve developed a structured approach to PR naming:
Format: <APP-ID>-<VERSION>-<ORDER> | <BRANCH> | <DESCRIPTION>
This naming convention solves several problems:
- Dependency tracking: Order numbers (0, 1, 2…) show the merge sequence for stacked PRs
- Version grouping: All PRs for version 0.7.1 start with
FN-0.7.1- - Quick context: Branch names and descriptions provide immediate context without opening the PR
We’ve automated this with custom Claude commands (more on this later) that analyze the PR chain, extract versions from our config files, and generate consistent titles. When you’re dealing with 5-10 PRs in flight, this structure becomes essential for keeping everyone aligned on what merges when.
Last week’s avalanche
Git Worktrees are MVPs
Git worktrees have become indispensable for AI-accelerated development. When you have multiple AI “genies” working on different problems across the codebase simultaneously, context switching becomes a major bottleneck.
While you’re in the middle of implementing a feature and waiting for Claude to generate code, you often need to review someone else’s PR. Rather than checking out a new branch in your current workspace and breaking “your flow” (aka Claude context), we maintain 1-2 additional worktrees specifically for PR reviews.
This setup lets us stay productive during AI generation cycles and keeps our main development context intact while handling the constant stream of reviews that AI-generated code requires.
Custom Claude Commands for Development Workflows
Beyond PR naming, we’ve built custom Claude commands for most of our development workflows for managing the increased complexity that comes with AI-accelerated development:
- Release management: Commands that handle version bumping, changelog generation, and release preparation
- Error monitoring: Query Sentry MCP for recent issues and correlate them with recent deployments
- PR chain management: Automatically merge PRs downstream across stacked PR chains. Any conflicts are fixed manually
These automations weren’t strictly necessary in our slower, pre-AI workflow. But when you’re moving fast and managing multiple concurrent features, having these workflows scripted becomes critical for maintaining quality.
Intensified Code Review Process
The thing about AI is that it is not going to take responsibility and get shouted at when things break in production. You still need to understand what’s happening in your codebase to protect your rear-end.
Our PR review process has become more rigorous:
- Self-review first: Every developer reviews their own AI-generated PR thoroughly before submitting
- Complexity-based assignment: Simple changes get one reviewer, complex ones get two
- More aggressive reviews: We learned early that it’s easy to gloss over AI-generated code, so we’ve become more nitpicky
- Knowledge propagation: For complex stories, multiple reviewers ensure the changes are well-understood across the team
Test Quality Over Quantity
With AI writing most of the implementation code, we’ve had to double down on test quality. AI tends to write extremely brittle tests - the kind where any line change breaks everything.
Currently, we focus on:
- Following existing conventions: Tests should match our established patterns and use proper fixtures
- Behavioral testing: Focus on what users actually care about, not implementation details
- Writing maintainable tests: Resist AI’s tendency toward over-specific, fragile assertions
Alternating Rhythm: Code Days vs Review Days
The time allocation shift has been dramatic. Previously, we spent most of our sprint writing code, with PR reviews clustered in the final days. Now it’s flipped - most time goes to reviewing the mountain of AI-generated PRs.
Our solution: alternating days within a week/iteration
- Day 1: Code generation
- Day 2: Reviews and merges
- Day 3: Code generation
- Day 4: Reviews and merges
- Day 5: Backlog cleanup, admin, and validation
This rhythm prevents the PR avalanche from becoming unmanageable.
Cross-Functional Teams are Essential
Another change, which is obvious in retrospect, is the value of having team members who can work across the full stack.
Previously, some of us had fairly specialized roles - one person would handle the backend API changes, then hand it off to a frontend developer to update the UI. The handoff and coordination overhead meant that even simple features often stretched across multiple weeks as work passed between team members.
With AI writing most of the code, it can generate both backend API endpoints and the corresponding frontend components equally well, having the same person handle a feature end-to-end eliminates most of the coordination overhead. A developer who understands both sides of the stack can now complete entire user stories independently, from database schema changes through API development to UI implementation.
Since verification and validation are the critical “human” aspects of feature development now, this is a huge accelerant to get things done and people who are cross functional can make laps around those who are not.
Results
Velocity: 2x, Not 10x
The team is genuinely happy with how this has played out. Our velocity has roughly doubled across the board - measured by story points, which we track religiously at Netrin.
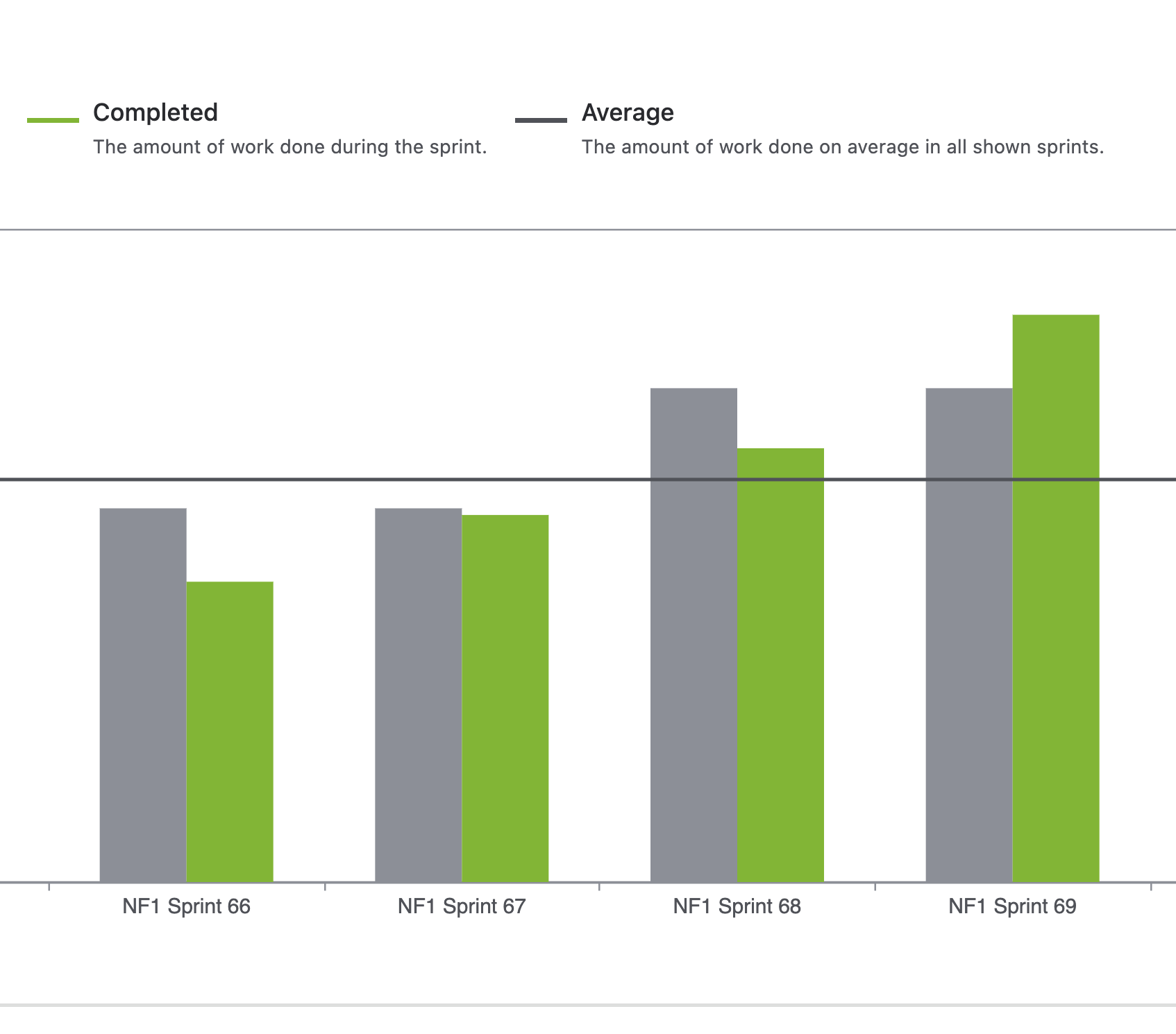
Despite what you might think, we actually don’t hate Jira
You’ll see claims online about 10x productivity gains, but that hasn’t been our experience. For a small team like ours, 2x feels realistic and sustainable. More experienced developers seem to extract slightly better gains from AI tools, but everyone has seen meaningful productivity improvements.
The TODO List Finally Gets Attention
With doubled velocity, we’re finally tackling those perpetual TODO items that every codebase accumulates. More importantly, we’re shipping user delight features - the small touches that make products feel polished but never make it onto the roadmap because “nobody’s asking for this specifically.”
I suspect AI will raise the bar for UI/UX quality across the board. When implementation becomes cheaper, polish becomes more viable.
Architecture Creep is very hard to defend against
It’s not all sunshine and doubled velocity.
When adding features becomes this convenient, it’s incredibly tempting to just… add them. AI makes it so easy to implement a quick fix or new capability that you don’t always step back to consider how it fits into the broader system architecture.
We’ve caught ourselves shipping features that work perfectly but don’t belong where we put them. The convenience factor is almost too good - why spend time architecting the proper solution when AI can give you something that works right now?
We have to be absolutely zen to be disciplined about architectural reviews and system design discussions before we let AI loose on implementation. I actually believe the code quality of new code has declined maybe 10% in the last few weeks, but that seems like a reasonable tradeoff for the 100% increase in velocity that we see.
The Million Dollar Question
So, is software engineering becoming obsolete?
I believe it’s exactly the opposite. Yes, fewer people will be needed for pure code generation (I do worry about the huge lower-end consulting economy), but the core bottleneck of software engineering has always been communication - understanding what exactly the product needs and translating that into working systems.
That bottleneck hasn’t moved. The hardest part was never writing the code. When it takes 18 months for an edit feature in Twitter to go from ideation to production, that is not because they were writing code for 17 months on this feature.
Requirements are complex and (human beings are predictably bad) at explaining what they need very clearly.
If anything, AI makes good software engineering skill more valuable, not less.